运维之三大监控对比
1. zabbix
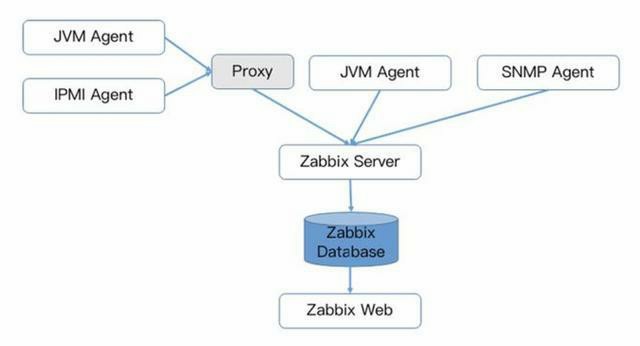
Zabbix核心组件主要是Agent和Server,其中Agent主要负责采集数据并通过主动或者被动的方式采集数据发送到Server/Proxy,除此之外,为了扩展监控项,Agent还支持执行自定义脚本。Server主要负责接收Agent发送的监控信息,并进行汇总存储,触发告警等。
Zabbix由于使用了关系型数据存储时序数据,所以在监控大规模集群时常常在数据存储方面捉襟见肘。所以从Zabbix 4.2版本后开始支持TimescaleDB时序数据库,不过目前成熟度还不高。
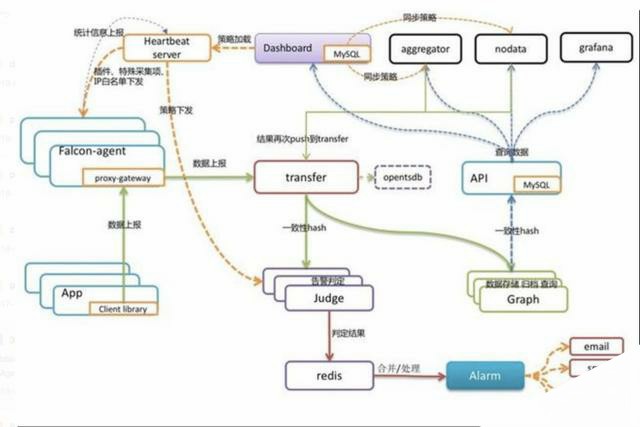
2. falcon
3. prometheus
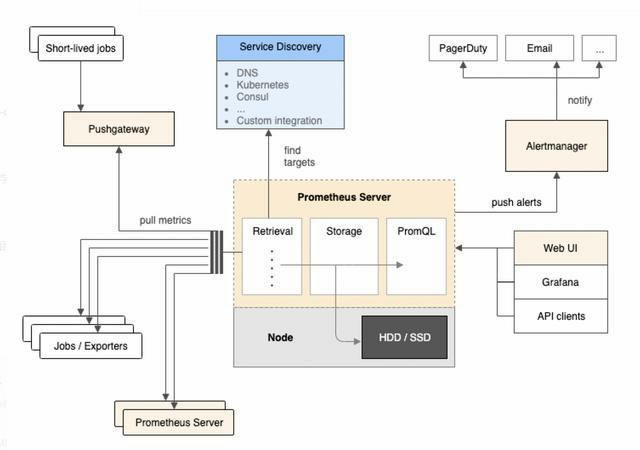
Prometheus Server负责定时在目标上抓取metrics(指标)数据并保存到本地存储里面。Prometheus采用了一种Pull(拉)的方式获取数据,不仅降低客户端的复杂度,客户端只需要采集数据,无需了解服务端情况,而且服务端可以更加方便的水平扩展。
如果监控数据达到告警阈值Prometheus Server会通过HTTP将告警发送到告警模块alertmanger,通过告警的抑制后触发邮件或者webhook。Prometheus支持PromQL提供多维度数据模型和灵活的查询,通过监控指标关联多个tag的方式,将监控数据进行任意维度的组合以及聚合。
对比:
开发语言 便捷易部署(promehteus) 系统成熟度(zabbix)20多年 系统扩展性 Zabbix和Open-Falcon都可以自定义各种监控脚本,并且Zabbix不仅可以做到主动推送,还可以做到被动拉取,Prometheus则定义了一套监控数据规范,并通过各种exporter扩展系统采集能力。 数据存储 Zabbix采用关系数据库保存,这极大限制了Zabbix采集的性能,Nagios和Open-Falcon都采用RDD数据存储 ,Prometheus自研一套高性能的时序数据库,在V3版本可以达到每秒千万级别的数据存储,通过对接第三方时序数据库扩展历史数据的存储; 配置复杂度 Prometheus只有一个核心server组件,其他系统配置相对麻烦,尤其是Open-Falcon。 社区活跃度 Prometheus在这方面占据绝对优势,社区活跃度最高,并且受到CNCF的支持 容器支持 Prometheus开始成为主导及容器监控方面的标配Prometheus功能介绍

(1) prometheus的指标类型
Counter(计数器):计数统计,累计多长或者累计多少次等。它的特点是只增不减,譬如HTTP访问总量; Gauge(仪表盘):数据是一个瞬时值,如果当前内存用量,它随着时间变化忽高忽低。如果需要了解某个时间段内请求的响应时间,通常做法是使用平均响应时间,但这样做无法体现数据的长尾效应。例如,一个HTTP服务器的正常响应时间是30ms,但有很少几次请求耗时3s,通过平均响应时间很难甄别长尾效应,所以Prometheus引入了Histogram和Summary。
Histogram(直方图):服务端分位,不同区间内样本的个数,譬如班级成绩,低于60分的9个,低于70分的10个,低于80分的50个。 Summary(摘要):客户端分位,直接在客户端通过分位情况,还是用班级成绩举例:0.8分位的是,80分,0.9分为85分,0.99分为的是98分(2) prometheus的client应用方式
客户端集成client,提供metrics接口查询 通过exporter方式(3) prometheus的存储方式
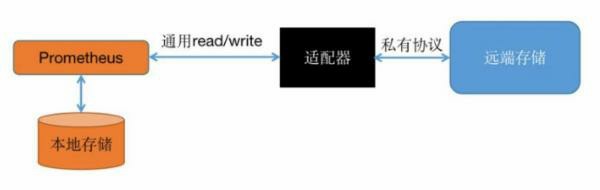
Prometheus提供了两种数据持久化方式:
一种是本地存储,通过Prometheus自带的tsdb(时序数据库),将数据保存到本地磁盘,为了性能考虑,建议使用SSD。但本地存储的容量毕竟有限,建议不要保存超过一个月的数据。Prometheus本地存储经过多年改进,自Prometheus 2.0后提供的V3版本tsdb性能已经非常高,可以支持单机每秒1000w个指标的收集。 另一种是远端存储,适用于大量历史监控数据的存储和查询。通过中间层的适配器的转化,Prometheus将数据保存到远端存储。适配器实现Prometheus存储的remote write和remote read接口并把数据转化为远端存储支持的数据格式。目前,远端存储主要包括OpenTSDB、InfluxDB、Elasticsearch、M3db、Kafka等,其中M3db是目前非常受欢迎的后端存储。(4) prometheus的查询方式
和关系型数据库的SQL类似,Prometheus也内置了数据查询语言PromQL,它提供对时间序列数据丰富的查询,聚合以及逻辑运算的能力。一条PromQL主要包括了指标名称、过滤器以及函数和参数。并且指标可以进行数据运算。
(5) prometheus的监控方式
Prometheus配置监控对象有两种方式,一种是通过静态文件配置,另一种是动态发现机制,自动注册监控对象。
Prometheus动态发现目前已经支持Kubernetes、etcd、Consul等多种服务发现机制,动态发现机制可以减少运维人员手动配置,在容器运行环境中尤为重要,容器集群通常在几千甚至几万的规模,如果每个容器都需要单独配置监控项不仅需要大量工作量,而且容器经常变动,后续维护更是异常麻烦。针对Kubernetes环境的动态发现,Prometheus通过watch kubernetes api动态获取当前集群所有服务和容器情况,从而动态调整监控对象
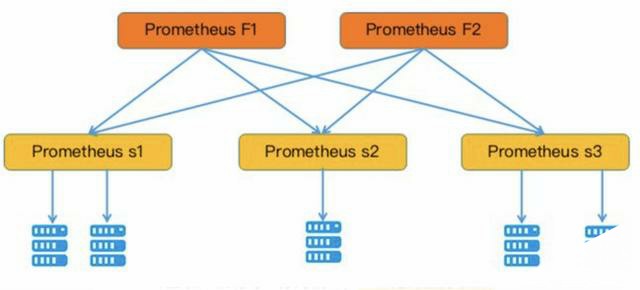
为了扩展单个Prometheus的采集能力和存储能力,Prometheus引入了“联邦”的概念。
多个Prometheus节点组成两层联邦结构,如图所示,上面一层是联邦节点,负责定时从下面的Prometheus节点获取数据并汇总,部署多个联邦节点是为了实现高可用
并且联邦机制可以分为俩种,一种是跨服务联合,一种是分层联邦。
跨服务联合,从不同的源抓取特定的服务的监控数据,然后做聚合处理; 分层联邦,就向一颗树,更高级别的prometheus服务从大量次级服务器收集聚合时间序列数据,然后去统一制定告警规则,分发触发事件。除此之外,prometheus可以依靠Thanos外挂服务,实现prometheus集群化、以及数据长期存储的功能,有兴趣的可以了解下。其实在prometheus2.0自身使用remote-wirte,remote-read接口已经解决了数据长期存储的问题了。预计3.0会做出更大的提升,尤其是prometheus的集群化。
